In this course, we'll dive into the world of sales data analysis using the dataacademykz.superstore.sales dataset. You'll learn essential SQL techniques to extract insights from sales data.
Task #1: Creating a Copy of the Dataset
To begin, it's important to create your own working copy of the dataset. This ensures that your analysis won't affect the original data. Execute the following query, but don't forget to replace your_project_name and your_dataset_name with a name of your choice:
Running this query in Google BigQuery will give you a clean slate to work with.
Task #2: Calculating Sales Amount Without a Discount
In sales analysis, determining the pre-discount sales amount is vital for understanding the gross revenue and for calculating key financial metrics like the Cost of Goods Sold (COGS). This requires adjusting the sales figures to account for any discounts given. The formula to calculate sales without a discount is:
Sales without a discount = Sales / (1 – Discount)
Objective: Create a new column named 'Sales_Without_Discount' in the new dataset that you will create that represents the sales amount before any discount is applied. Round the result of the column to one decimal.
Expected Result: A new table will be created with an additional column showing the sales amount without discounts.
Data Source:dataacademykz.superstore.sales
CREATE OR REPLACE TABLE`your_project_name.your_dataset_name.sales_analytics`ASSELECT*,
ROUND(Sales / (1 - Discount), 1) AS Sales_Without_Discount
FROM`dataacademykz.superstore.sales`
Explanation:
Imagine you’re looking at your store's sales records and you want to figure out how much money you would have made before any discounts were given.
This query recalculates each sale as if no discount had been applied, giving you a picture of what the original, undiscounted sales figures would look like.
It then creates a new list (or table) of these recalculated sales figures, including all the original information plus this new 'pre-discount' sales amount.
This helps you understand your store's sales performance without the impact of discounts, showing what your revenue might have looked like without them.
Technical Breakdown:
This SQL query calculates the sales amount without a discount and creates a new table with this data. Here's the technical breakdown:
Objective: The goal is to compute the pre-discount sales amount for each record in the dataset, effectively reversing the discount effect on the sales figure.
Formula Application:
The query uses the formula Sales / (1 - Discount) to calculate the sales amount before any discount was applied.
ROUND(Sales / (1 - Discount), 1) rounds the result to one decimal place for precision.
CREATE OR REPLACE TABLE:
The CREATE OR REPLACE TABLE statement is used to create a new table (or replace it if it already exists) in the specified project and dataset.
This new table will include all existing columns from the original dataacademykz.superstore.sales table, plus the additional Sales_Without_Discount column.
Data Source and Selection:
The data is sourced from the dataacademykz.superstore.sales table.
The * operator selects all existing columns from this table, and the new calculated column is appended.
Result:
The output is a new table that mirrors the original sales table but includes an additional column, Sales_Without_Discount, showing the sales amount before the discount was applied for each record.
Task #3: Calculating COGS (Cost of Goods Sold)
The Cost of Goods Sold (COGS) is an essential metric in financial analysis, particularly in sales and profitability assessments. It represents the direct costs attributable to the production of the goods sold by a company. In this task, we will calculate COGS for each item by subtracting the Profit from the Sales_Without_Discount.
Objective: Create a new column named 'COGS' in the new dataset, representing the Cost of Goods Sold for each item.
Expected Result: A new table that you have already created will be updated, including the 'COGS' column, calculated for each record.
Data Source:your_project_name.your_dataset_name.sales_analytics
CREATE OR REPLACE TABLE`your_project_name.your_dataset_name.sales_analytics`ASSELECT*,
ROUND(Sales_Without_Discount - Profit, 1) AS COGS
FROM`your_project_name.your_dataset_name.sales_analytics`
Explanation:
Imagine you’re running a store and want to find out the actual cost of the products you’ve sold, excluding your profits.
This query calculates the COGS for each item sold. It does this by figuring out what the sales amount would have been without any discounts and then subtracting the profit from this amount.
It then creates a new list (or table) of these COGS figures, including all the original sales information plus this new 'cost of goods sold' amount.
This helps you understand the direct costs associated with the products sold, providing a clearer picture of the store's profitability.
Technical Breakdown:
This SQL query is designed to calculate the Cost of Goods Sold (COGS) for each record in a dataset and create a new table with this data. Here's the technical breakdown:
Objective: The goal is to compute COGS, a key financial metric that helps in understanding the direct costs incurred in selling products.
Formula Application:
The query calculates COGS by subtracting the Profit from the Sales_Without_Discount column.
ROUND(Sales_Without_Discount - Profit, 1) rounds the result to one decimal place for precision.
CREATE OR REPLACE TABLE:
The CREATE OR REPLACE TABLE statement is used to create a new table (or replace it if it already exists) in the specified project and dataset.
This new table will include all existing columns from the your_project_name.your_dataset_name.sales_analytics table, plus the additional COGS column.
Data Source and Selection:
The data is sourced from the your_project_name.your_dataset_name.sales_analytics table.
The * operator selects all existing columns from this table, and the new calculated column is appended.
Result:
The output is a new table that mirrors the original sales analytics table but includes an additional column, COGS, showing the cost of goods sold for each record.
It's important to highlight that we don't require the use of a GROUP BY clause in this context because we are not performing any aggregation. Instead, every row in the result set undergoes independent calculations based on the respective row in the source table. The expression ROUND(Sales / (1 - Discount), 1)is evaluated individually for each row, operating on the specific values within that row rather than across groups of rows. Hence, there is no necessity for a GROUP BY clause in this scenario.
Task #4: Analyzing Sales by Sub-Category Within Categories
Categorizing sales by sub-category within each category is a valuable analytical approach. It helps in understanding which product categories and sub-categories are performing best in terms of sales. This analysis can inform strategic decisions such as inventory management, marketing focus, and product development.
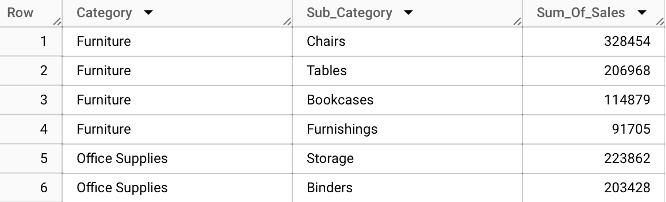
Objective: Calculate the total sales for each sub-category within its respective category and display the results sorted by category and then by sales in descending order.
Expected Result: A sorted list showing the sum of sales for each sub-category within each category, helping to identify the top-performing areas.
Data Source:dataacademykz.superstore.sales_analytics
SELECT
Category,
Sub_Category,
SUM(Sales) AS Sum_Of_Sales
FROM`dataacademykz.superstore.sales_analytics`GROUP BY
Category,
Sub_Category
ORDER BY
Category,
SUM(Sales) DESC
Explanation:
Think of this query as creating a detailed sales report for a store. It's like grouping together all the items sold, not just by their main category (like Electronics, Furniture) but also by their sub-categories (like Phones, Chairs).
We add up all the sales in each sub-category to see how much each one contributed to the store's overall sales.
Then, we list them, category by category, starting with the sub-categories that sold the most.
It's a way to see which specific types of products are the big sellers in each part of the store.
Technical Breakdown:
This SQL query is designed to aggregate sales data by sub-categories within each broader category, providing a detailed view of sales performance across different product lines. Here's the technical breakdown:
Objective: The goal is to calculate the total sales for each sub-category within each broader category.
Aggregation and Grouping: The SUM(Sales) AS
Sum_Of_Sales clause computes the total sales for each combination of Category and Sub_Category. The GROUP BY Category, Sub_Category clause ensures that sales are aggregated separately for each sub-category within each category.
Sorting: The ORDER BY Category, SUM(Sales)
DESC clause first sorts the results by Category and then by the total sales within each category in descending order.
Result: The output presents a structured view of total sales, categorized by each sub-category within the broader categories, highlighting top-performing and underperforming areas.
Task #5: Analyzing State-wise Sales Performance for "Technology" Category
Focusing on specific product categories is often crucial in business analytics to understand market dynamics and customer preferences in different regions. In this task, the aim is to analyze the sales performance of the "Technology" category across different states. This will help in identifying which states are leading in sales for technology products and where there may be room for growth or improvement.
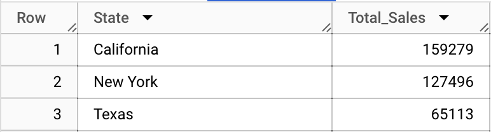
Objective: Determine the total sales for the "Technology" category in each state, and rank the states based on their sales performance in this category.
Expected Result: A list of states sorted by their total sales in the "Technology" category, from highest to lowest.
Data Source:dataacademykz.superstore.sales_analytics
SELECT
State,
SUM(Sales) AS Total_Sales
FROM`dataacademykz.superstore.sales_analytics`WHERE
Category = 'Technology'GROUP BY
State
ORDER BY
Total_Sales DESC
Explanation:
Imagine you’re running a chain of electronics stores and want to see how well your technology products are selling in different states. This query is like going through your sales records, state by state, but only looking at technology items like computers, phones, and gadgets.
For each state, we add up all the sales of technology products.
Then, we list the states, starting with the one where technology products sold the most.
This way, you can see which states love their tech the most and which might need a bit more marketing push or inventory adjustments.
Technical Breakdown:
This SQL query is crafted to analyze sales data by state specifically for the 'Technology' category, highlighting regional sales performance. Here's the technical breakdown:
Objective: The goal is to compute total sales for the 'Technology' category, broken down by each state.
Filtering: The WHERE Category =
'Technology' clause narrows down the dataset to only include sales from the 'Technology' category. This ensures that the analysis is focused and relevant.
Aggregation and Grouping: The SUM(Sales) AS
Total_Sales clause calculates the total sales for each state. The GROUP BY State clause groups the data by state, ensuring that sales are aggregated separately for each.
Sorting: The ORDER BY Total_Sales DESC clause sorts the results in descending order based on total sales. This ranking allows for easy identification of states with the highest sales in the 'Technology' category.
Result: The output presents state-wise total sales figures for the 'Technology' category, enabling a clear view of regional market performance within this specific category.
Task #6: Identifying the Top-5 Products by Revenue in the Technology Category
In the field of sales and product management, identifying the highest revenue-generating products within a specific category is crucial for strategic decision-making. This task focuses on pinpointing the top-5 products in terms of revenue within the "Technology" category. Such an analysis is instrumental in understanding customer preferences and market trends, and it can guide inventory and marketing strategies.
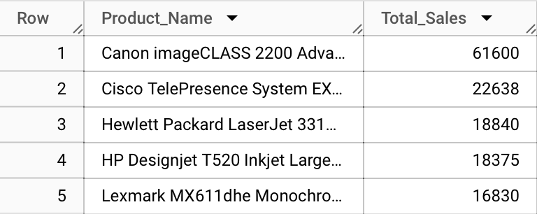
Objective: Determine the top-5 products by revenue in the "Technology" category.
Expected Result: A list of the top-5 technology products ranked by their total sales, from highest to lowest.
Data Source:dataacademykz.superstore.sales_analytics
SELECT
Product_Name,
SUM(Sales) AS Total_Sales
FROM`dataacademykz.superstore.sales_analytics`WHERE
Category = 'Technology'GROUP BY
Product_Name
ORDER BY
Total_Sales DESCLIMIT
5
Explanation:
Think of this query as creating a leaderboard for technology products in terms of sales. It's like running a race where the products are competitors, and the sales revenue is how fast they run.
We're focusing only on the technology race – other categories aren't included.
Each product's "race time" is the total amount of money it has made from sales.
In the end, we only want to see the top five finishers – the products that sold the most.
Technical Breakdown:
This SQL query is structured to rank products in the 'Technology' category based on their total revenue, highlighting the top five performers. Here's the technical breakdown:
Objective: The aim is to calculate the total sales revenue for each product within the 'Technology' category and identify the top five in terms of sales.
Filtering: The WHERE Category =
'Technology' clause filters the data to include only sales from the 'Technology' category, ensuring that the analysis is category-specific.
Aggregation and Grouping: The SUM(Sales) AS
Total_Sales clause computes the total sales revenue for each product. The GROUP BY Product_Name clause groups the data by product name, allowing for the aggregation of sales at the product level.
Sorting and Limiting: The ORDER BY Total_Sales
DESC clause sorts the products based on their total sales in descending order. The LIMIT 5 clause then restricts the output to the top five products, based on this sales ranking.
Result: The output presents the top five products in the 'Technology' category by total sales, providing a clear view of the highest revenue-generating products in this category.
Task #7: Discovering the Most Popular Products by Order Count
In the field of sales and marketing, understanding product popularity is as crucial as knowing revenue figures. Popularity can be gauged by the number of times a product appears in orders, offering insights into consumer preferences and demand patterns. This task aims to identify which products are most frequently ordered by counting the distinct orders associated with each product.
Objective: Determine the products that appear in the greatest number of distinct orders.
Expected Result: A list of products ranked by their order count, revealing the most popular products based on how frequently they are ordered.
Data Source:dataacademykz.superstore.sales_analytics
SELECT
Product_Name,
COUNT(DISTINCT(Order_ID)) AS Number_of_Orders
FROM`dataacademykz.superstore.sales_analytics`GROUP BY
Product_Name
ORDER BY
Number_of_Orders DESC
Explanation:
Imagine you're trying to find out which products in your store are the customer favorites. This query is like going through your sales records and counting how many times each product gets bought, but making sure you only count each order once, even if the product was bought in bulk.
We're tallying up how many different shopping trips included each product.
Then, we list the products starting with the ones that were part of the most shopping trips, showing us the crowd favorites.
Technical Breakdown:
This SQL query is devised to evaluate product popularity based on the frequency of their occurrence in orders. Here's the technical breakdown:
Objective: The aim is to count how many distinct orders each product appears in, thereby assessing product popularity.
Aggregation and Counting: The COUNT(DISTINCT(Order_ID)) AS Number_of_Orders clause is key here. It counts the number of unique orders for each product. This approach ensures that even if a product appears multiple times in a single order, it is only counted once for that order.
Grouping and Sorting: The GROUP BY
Product_Name clause groups the data by each product. The ORDER BY Number_of_Orders DESC clause then orders these groups by the count of distinct orders, in descending order.
Result: The output ranks products by the number of distinct orders they appear in, providing a clear indication of which products are most popular based on order frequency.