In this step, we will conduct basic column analytics to gain deeper insights into the dataset by exploring specific questions.
Task #1: What is the Time Range of the Dataset?
For effective data analysis and trend forecasting, understanding the time span covered by our dataset is crucial. This task aims to identify the temporal boundaries of our data by determining the earliest and latest order dates recorded in the Superstore sales data.
Objective: The goal is to find the date range of the orders in the Superstore sales data, specifically the earliest (minimum) and latest (maximum) order dates.
Expected Result: The result should display two dates: the earliest ('min_order_date') and the latest ('max_order_date') found in the 'Order_Date' column of the dataset.
Data Source:dataacademykz.superstore.sales
SELECTMIN(Order_Date) AS min_order_date,
MAX(Order_Date) AS max_order_date
FROM`dataacademykz.superstore.sales`
Explanation:
Imagine you're looking through an old record book of sales and want to know when the first and last sales were made.
This query is like flipping to the very first and last pages of your sales record book to see the dates.
It tells you the date of the very first order and the date of the very latest order in your records.
It's a quick way to get an idea of how long your store has been running and making sales.
Technical Breakdown:
This SQL query is designed to identify the earliest and latest order dates in the Superstore sales dataset. Here's the technical Breakdown:
Selection of Dates:
The query uses the MIN(Order_Date) AS min_order_date to find the earliest (oldest) order date in the dataset.
It also uses MAX(Order_Date) AS max_order_date to find the latest (most recent) order date in the dataset.
Result:
The output includes two dates: the earliest date (min_order_date) and the latest date (max_order_date) that orders were placed in the Superstore sales dataset.
Task #2: How Many Orders Do We Have in the Dataset?
Understanding the volume of orders is a critical aspect of business analysis, as it reflects the scale of operations and customer engagement. This task focuses on quantifying the total number of orders placed, as captured in the Superstore sales data.
Objective: The task is to determine the total number of distinct orders that have been placed, as recorded in the Superstore sales data.
Expected Result: 5,009
Data Source:dataacademykz.superstore.sales
SELECTCOUNT(DISTINCT(Order_ID)) AS number_of_orders
FROM`dataacademykz.superstore.sales`
Result Interpretation:
Executing this query reveals a total of 5,009 unique orders in the dataset. This indicates an average of approximately two rows per order, given the total dataset size of 9,994 rows (9,994 / 5,009 ≈ 2). This ratio implies that, on average, each order is detailed across two rows in the dataset.
Explanation:
Imagine you have a huge pile of order receipts and you want to know how many different sales orders you've handled.
This query is like going through each receipt and counting up how many different orders there were, making sure not to count the same order twice.
It gives you a number that shows how many separate sales transactions have taken place.
This is a handy way to get a quick sense of how much business has been done in terms of the number of orders.
Technical Breakdown:
This SQL query calculates the total number of unique orders in the Superstore sales dataset. Here's the technical Breakdown:
Use of COUNT and DISTINCT:
The query uses COUNT(DISTINCT(Order_ID)) to count the number of unique Order_ID values in the dataset.
DISTINCT ensures that each order ID is counted only once, regardless of how many times it appears in the dataset.
Result:
The output will be a single number, representing the total count of unique orders in the Superstore sales data.
Task #3: How Many Customers Do We Have in the Dataset?
Gaining insight into the size of our customer base is essential for strategic planning and resource allocation. This task aims to quantify the number of unique customers we serve, as recorded in our dataset.
Objective: Determine the total number of unique customers represented in the dataset.
Expected Result: 793
Data Source:dataacademykz.superstore.sales
SELECTCOUNT(DISTINCT(Customer_ID)) AS number_of_customers
FROM`dataacademykz.superstore.sales`
Result Interpretation:
Upon executing the query, the result shows that there are 793 unique customers. This finding suggests that, on average, each customer has placed approximately six orders, as indicated by the ratio of the total number of orders (5,009) to the number of unique customers (793), i.e., 5,009 / 793.
Explanation:
Imagine you're looking at your store's sales records and you want to find out how many different people have shopped at your store.
This query is like counting every unique customer who ever made a purchase, making sure not to double-count anyone.
It gives you the total number of individual customers who have bought items from your store.
This helps you understand how large your customer base is, showing how many different people have engaged with your business.
Technical Breakdown:
This SQL query is designed to calculate the total number of unique customers who have made purchases, as recorded in the Superstore sales dataset. Here's the technical Breakdown:
Use of COUNT and DISTINCT:
The query utilizes COUNT(DISTINCT(Customer_ID)) to count the number of unique Customer_ID values in the dataset.
The DISTINCT keyword ensures that each customer ID is counted only once, even if it appears multiple times in the dataset (which would indicate multiple purchases by the same customer).
Result:
The output will be a single numerical value (793), indicating the total count of unique customers in the Superstore sales data.
Task #4: Which Shipping Options Are Available for Our Customers?
To enhance customer satisfaction and operational efficiency, it's important to understand the variety of shipping options we offer. This task involves analyzing the dataset to uncover the different shipping methods available to our customers.
Objective: Discover the range of shipping options available to customers as represented in the dataset.
Expected Result: The query is expected to yield a list of different shipping options.
Imagine you’re looking through your store's delivery records to see all the different ways customers can get their purchases shipped.
This query goes through all your sales and picks out each unique type of shipping, like "standard," "express," or "overnight."
It gives you a list showing every shipping option you've ever offered.
Technical Breakdown:
This SQL query is aimed at identifying all the different shipping options available to customers, as recorded in the Superstore sales dataset. Here's the technical Breakdown:
Use of DISTINCT:
The query utilizes DISTINCT Ship_Mode to list all unique values found in the Ship_Mode column of the dataset.
DISTINCT ensures that each shipping mode is listed only once, regardless of how frequently it appears in the dataset.
Result:
The output will be a list of the different shipping options that have been used in the transactions recorded in the Superstore sales data.
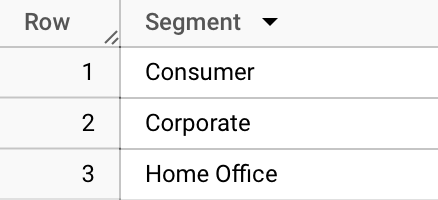
Task #5: Which Segments Do We Have?
Our dataset contains valuable information about customer classifications. Understanding these classifications is crucial for targeted strategies in marketing and product development.
Objective: Identify the different customer segments present in the dataset, based on the 'Segment' column.
Expected Result: The expected outcome of this query is to identify a finite set of distinct customer segments. It is anticipated to reveal specific segment names that classify the customers.
As you can see, there are only three segments – Consumer, Corporate, and Home Office. From the description of the dataset we know that: Segment => The segment where the Customer belongs. Explanation and Technical Breakdown of this solution is almost the same as for the solution above.
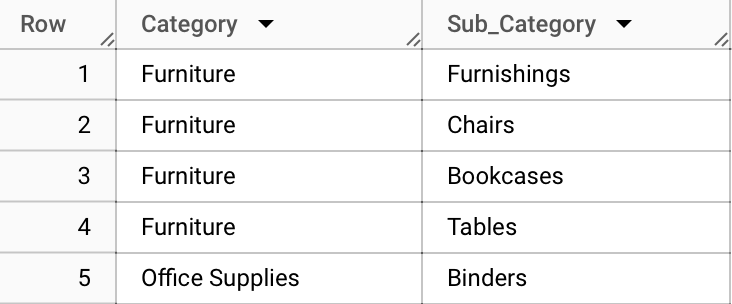
Task #6: What Are the Different Product Categories and Sub-Categories in Our Dataset?
To understand the range of products we deal with, it's essential to know the categories and sub-categories they belong to. This can be achieved by querying the Category and Sub_Category columns from our dataset.
Objective: Explore and list the various product categories and sub-categories available in the dataset, to gain a comprehensive understanding of the product range.
Expected Result: The expectation is to generate a list showcasing each unique combination of category and sub-category.
Data Source:dataacademykz.superstore.sales
SELECTDISTINCT
Category,
Sub_Category
FROM`dataacademykz.superstore.sales`ORDER BY Category
Explanation: This query will list each unique combination of product category and sub-category. We use SELECT
DISTINCT to ensure that each combination is listed only once. The results are then ordered first by Category and then by Sub_Category, providing a well-organized view of the product classification.